Hugging Face: The Artificial Intelligence Community Building the Future
Startup Spotlight #5

Every day, founders & operators everywhere are building new technologies and companies that should us optimistic about tomorrow. My goal: champion some of these founders, companies, and industry trends. Join thousands of investors, operators, and founders on the mailing list!!

Summary
Last fall, OpenAI shocked the world when they released GPT-3. The demos made artificial intelligence feel much more immediate and tangible than ever before. The industry, however, has quietly been accelerating, and the potential applications are rapidly expanding.
Significant advances in natural language processing (NLP), like GPT-3, are leading to a wave of innovation and opportunities. Within nine months of their launch, GPT-3 has already seen over 300 applications leverage their API. Examples range from tools to develop marketing copy (Copy.ai) to developing fictional storylines (Fable Studio).
GPT-3, however, is just one of many NLP models, and NLP models are just one genre of the machine learning model space. Researchers all over the world are developing new models with a variety of promising applications. Simultaneously, Engineers across the world are finding new ways to leverage these capabilities, but it can be challenging to keep up… until Hugging Face.
On the surface, Hugging Face 🤗 is unassuming, fun, and simple… as the emoji logo might suggest.
Despite raising ~$60M, there is a dearth of publicity surrounding the company… but there should not be. With over 10,000 models+, 1,000+ datasets, and 5,000+ companies using their products, Hugging Face has quietly become one of the fastest growing open source platforms in history.
They do this by bringing fun and simplicity to an extremely complex and technical field (Machine Learning Models). Starting with NLP models, Hugging Face has used their playful branding, clean UX, and customer-centric features to make NLP models simple. Now, however, Hugging Face is expanding beyond NLPs, so they can empower thousands of engineers to use any machine learning model across any category.
In the future, Hugging Face will be the “GitHub of Machine Learning”, providing the most powerful tools in the world to engineers within a few clicks.
In summary, do not let the fun emoji fool you. Hugging Face is powerful. Let’s walk through why.
What is Natural Language Processing (NLP)?
Machine Learning is a huge concept, so to best understand the potential for the industry (and Hugging Face specifically), let’s start by examining the genre Hugging Face started with: NLP models.
IBM defines NLP as “the branch of computer science—and more specifically, the branch of artificial intelligence or AI—concerned with giving computers the ability to understand text and spoken words in much the same way human beings can.”
Well, what does this actually mean?
In the most simple form, NLP is a model that can take text or spoken language as inputs and provide outputs similar to the way a human would. It may seem simple but consider how complex language can be.
For English, there are similar words like:
There vs. they’re vs. their
Your vs. you’re
Ate vs. eight
It gets a degree more complicated when you consider context, sentiment, idioms, etc.
For machines, comments like “break a leg”, “hang in there”, and “under the weather” are typically difficult to understand.
NLP models, however, are computer models that, when well trained, can begin to extract context and sentiment, so it can understand, and even predict, text as well as humans.
How does NLP work?
If you are a scientist in artificial intelligence, this explanation may make you cringe, but at a high level, I will attempt to explain the mechanics behind an NLP model.
At the most basic level, an NLP model studies enormous amounts of text or spoken word, and it begins to understand how the different words and characters are connected.
There are really three main steps to this:
Tokenize
Train
Apply

Exhibit 1: How does NLP work?
First, an NLP model tokenizes the dataset. Each word (or character potentially) is broken into “tokens.” In Exhibit 1, there is an example sentence: “Dogs are better than cats.” The model would break [Dogs] [are], [better], [than], and [cats] into separate tokens. It would do this across the entire dataset.
Once all of the words are tokenized, the model begins training. This is an extensive process. Consider this: GPT-3 has 175 billion parameters. These datasets can be massive.
Throughout the training process, the model analyzes each token, and it begins to assign predictive probabilities. This will allow the model to identify patterns. In the example above, it will eventually begin to recognize that when [Dogs], [are], and [better], then it can predict [than] and [cats] to follow in sequence.
Once the model is fully trained, it can begin to apply the learnings to fully understand the text.
Now, it is important to note that the capabilities of NLP models widely range. Obviously, if the dataset only consists of the sentence above, then the model would be lost if it came across the word “gorilla”.
This is where there are huge levels of complexity in NLP models. There are thousands of scientists much smarter than me working on these constantly. Scientists must be incredibly strategic about model design, as well as identifying a high-quality, large dataset to train the model. All of this is done with the end application of the model in mind.
These three steps give a very basic understanding of NLP models, and at an even more macro level, these are the fundamental concepts behind all ML models. Take a massive dataset. Segment into digestable components. Train the model to build predictive characteristics. Apply to the designed use case.
All of this is critical to understanding the future of this industry.
Why does NLP matter?
If a model can accurately understand and predict text or spoken word, then the opportunities to automate are pretty limitless. Likely, you have already encountered many NLP models.
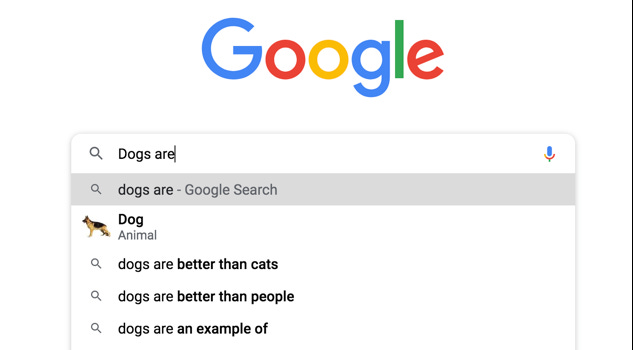
Exhibit 2: Google Search auto-complete example
When you type a search on Google, it will offer suggested completions.
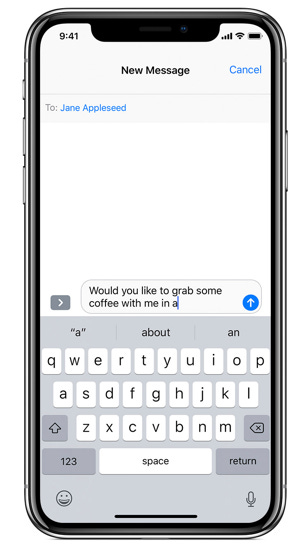
Exhibit 3: Apple iMessage auto-complete (Source)
If you have an Apple device, you will notice the suggested text after each word you type.
NLP usage is still nascent, but the applications continue to expand. OpenAI lists 40 current examples of applications using their API across Generation, Transformation, Translation, Answers, Classification, and Conversation.
Hugging Face provides models for 18 different tasks (See Exhibit 13 in Appendix). To simplify, I would consider that there are three primary functions that current Hugging Face models can be applied to: 1) Generation, 2) Classification, and 3) Other.

Exhibit 4: Current Hugging Face machine learning categories
In Generation, a model can take the inputs you provide and create a new set of outputs. Examples include:
You give the NLP model an e-book, and it generates a summarized abstract
You provide a product description, and the NLP model generates ad copy
You provide text in English and the NLP model generates the text in foreign languages
In classification, the model takes the inputs (e.g., data, text), and it segments the content into categories based on parameters. In this application, the model does not generate anything new, but rather, it leverages its knowledge to automatically separate content.
Hugging Face expanded beyond solely NLP model classification, and they have begun supporting computer vision (e.g., Image classification). Examples include:
You provide an audio clip with many voices, etc., and the NLP model separates it
You provide 1M different tweets, and the NLP model identifies all of the positive and negative sentiment tweets
Click and drag an image and have the computer classify / tag the image (Image Classification)
Recently, Hugging Face has successfully expanded beyond simply NLP models. For now, I have grouped these as “Other.” Early examples include:
Directly transcribing speech (Automatic Voice Detection)
Identify all images with a bike included (Computer Vision)
Email, social media, entertainment, work, etc. 90% of what we do involves some form of language, and much of that is focused on either understanding language (classifying it) or reacting to language (generating). For this reason, ML models (and NLP models specifically) will lead to remarkable applications in every aspect of our life, and as founder Clement Delangue says, “NLP is going to be the most transformation tech of the decade!”
The Problem: Bridging the gap between science and engineering
While NLP research and innovation continues to accelerate, there has been an industry headwind: the disconnect between science and engineering.

Exhibit 5: Bridging the gap between science and engineering
NLP models are primarily developed by artificial intelligence scientists (or researchers). There are many different NLP research organizations ranging from corporations to academic institutions to non-profits, and they are all producing different models
The engineers, however, are the stakeholders that would actually leverage these models within their organization (e.g., corporation).
The scientists need engineers to use their model, so they can gather data and accelerate their learning. The scientists, however, do not have time, abilities, or resources to market, sell, and deploy their model to organizations.
The engineers need these models to solve critical problems for their business, but the complex whitepapers and difficulty to deploy make model operationalization within their business extremely challenging.
Both parties would benefit from each other, but there is friction between the two that is both inefficient and hindering speed of innovation. While this has been very noticeable in the NLP model space, it will continue across many different Machine Learning fields.
The Solution: Hugging Face
Hugging Face is solving this problem. The Hugging Face platform brings scientists and engineers together, creating a flywheel that is accelerating the entire industry (Exhibit 6)

Exhibit 6: The three pillars of Hugging Face
Hugging Face does this with three primary pillars:
Open source library of models and datasets
Operationalizing capabilities
Community
First, Hugging Face features 10,000+ models in their open-source model library called Transformers. Combined with 1,000+ datasets, there is no larger set of resources for ML models (NLP models specifically) in the world.
Second, Hugging Face removes friction for engineers to deploy and operationalize ML models. Rather than crawl through extensive whitepapers scouring for the perfect model, Hugging Face provides recommendations based on your desired task.

Exhibit 7: Example of task recommendation (Source)
For each model published on Transformers, they provide a description, limitations, uses, details on how to use, and current usage information (downloads). The extensive information educates the engineer and provides a single source to search, compare, and select ML models.
Upon selection, Hugging Face enables deployment with 1-2 lines of code or a simple copy and paste.
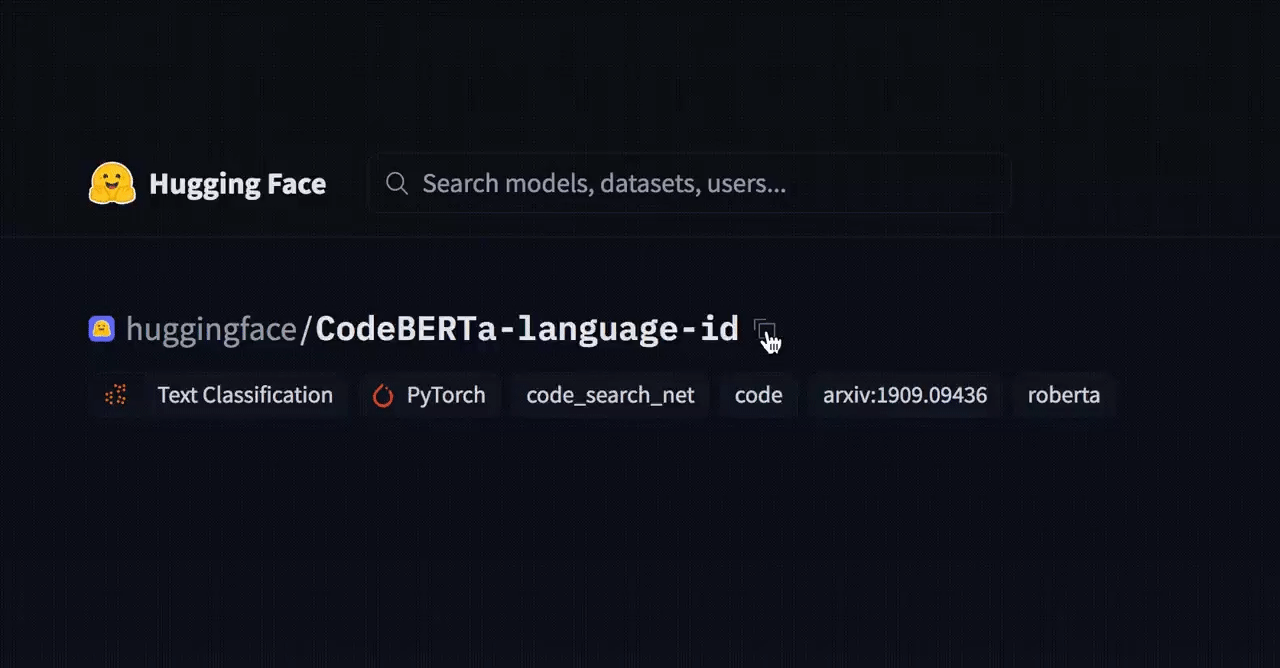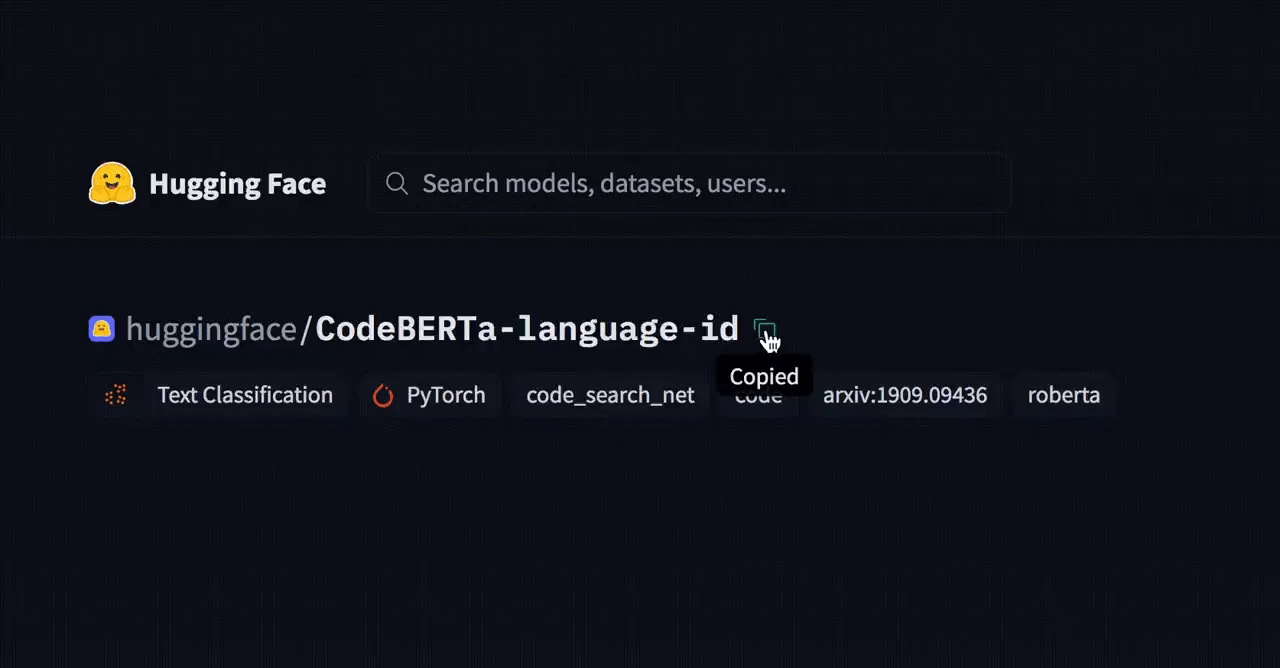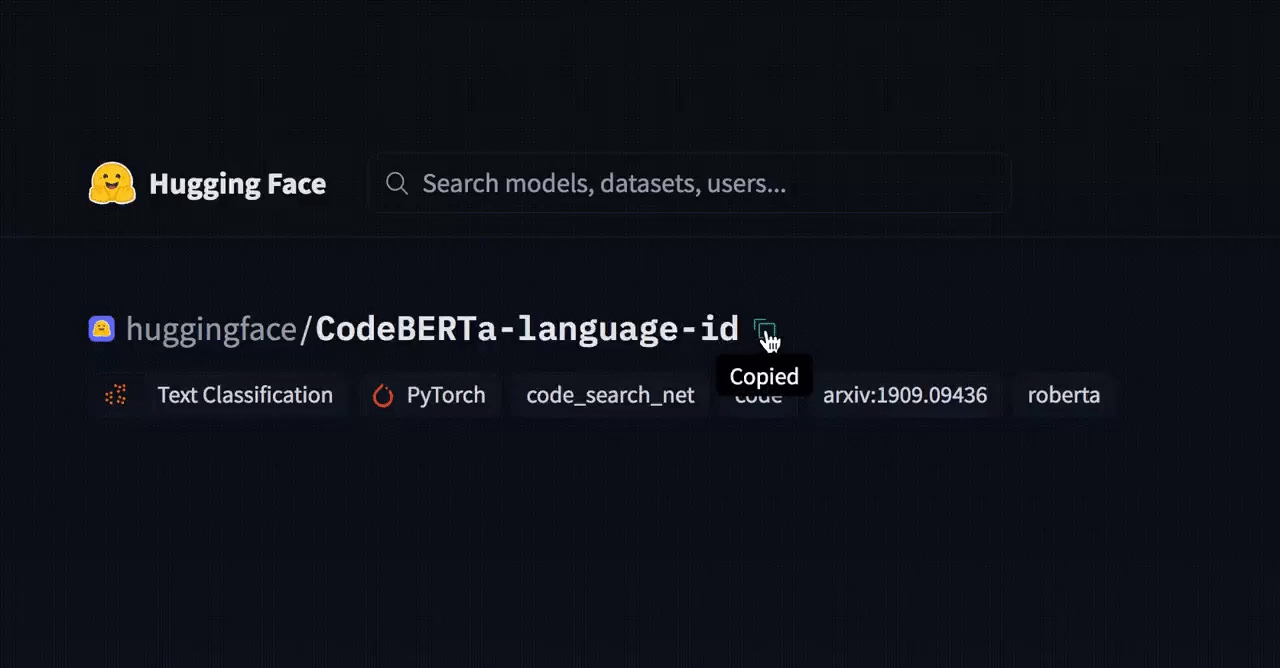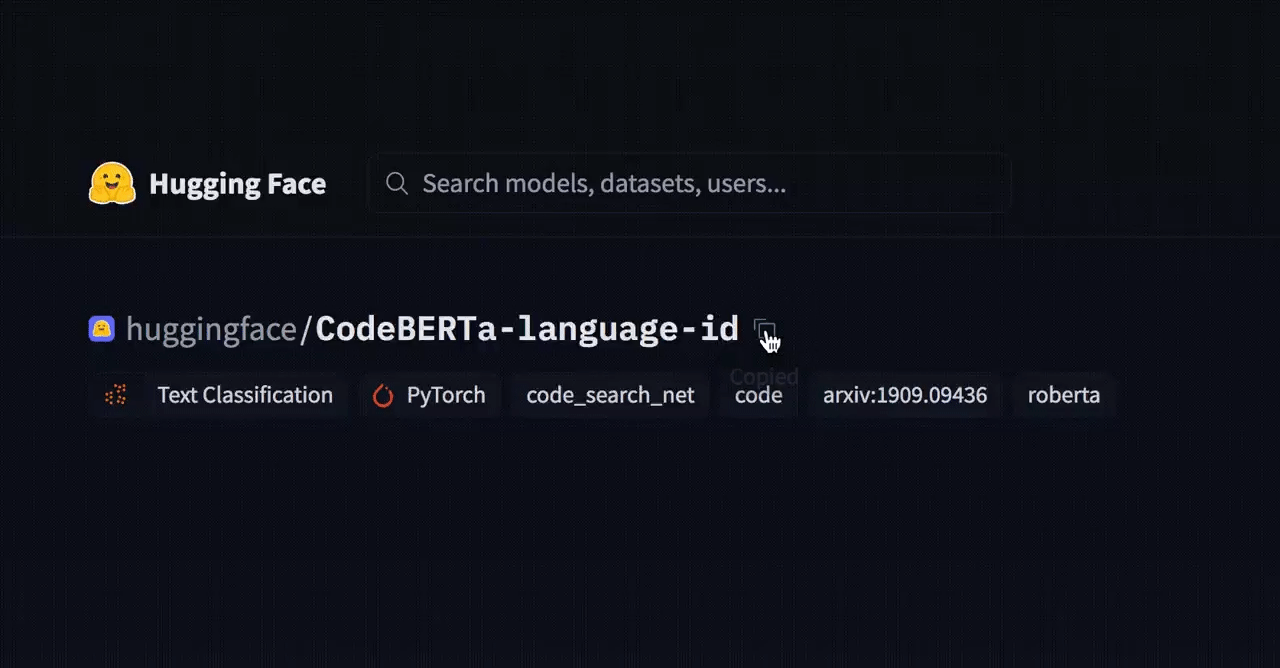
Exhibit 8: Copy & Paste ability
Once deployed, the Inference API can serve ML models in milliseconds, accelerating training and optimizing accuracy
Finally, Hugging Face pairs this with a large community of engineers. The forum has created an ML-specific community focused on accelerating the industry progress and creating new applications of these models. The endless resources and public discourse completes the feedback cycle for scientists, and it accelerates the adoption and learning of engineers.
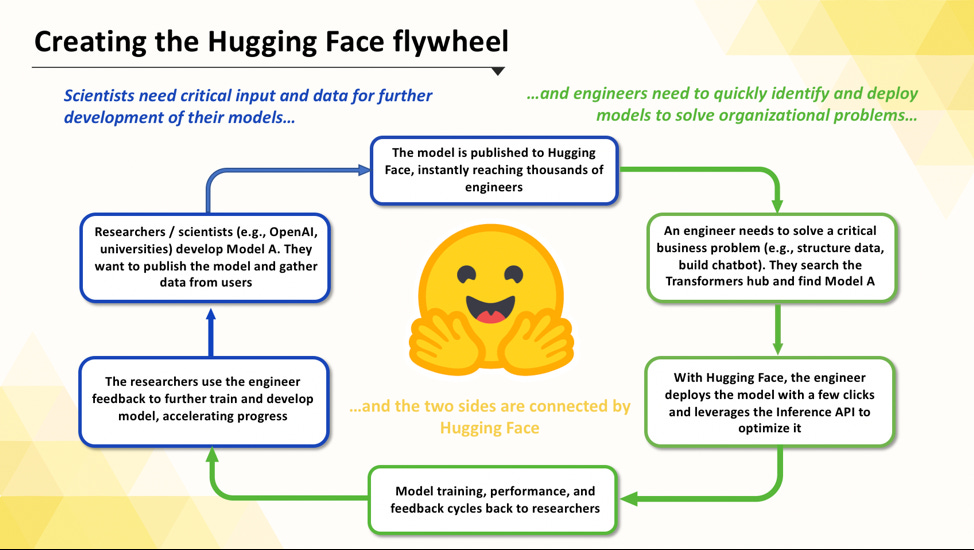
Exhibit 9: The Hugging Face Flywheel
Conclusion
In summary, the NLP space is one of the most exciting foundations for innovation in the next ten years.
NLP models are, however, just the beginning. Hugging Face will continue to expand the current library of models, becoming the “GitHub of Machine Learning.” As the market advances, Hugging Face has positioned itself to be the centerpiece of innovation, both facilitating and progressing the overall adoption and development of ML models.
Hugging Face will be the platform strategically positioned in the middle of one the largest next waves of innovation.
As more people embrace (hugging pun… get it?) NLP models, Hugging Face will increasingly become a company to watch, study, and admire.
Appendix
Investment score

Exhibit 10: Investment score
Problem Statement
Currently, there are two disconnected groups in machine learning (ML): A) Scientists and B) engineers.
Scientists are building ML models rapidly. They need people to use the models to further drive their research. Engineers could use these models to solve complex problems within their companies. The field is moving fast. The models are complex, and they are released rapidly, making it difficult to deploy. Hugging Face is the platform that connects research and science, allowing for easy operationalization.
Market Drivers
Growth
Digital transformation – Satya Nadella stated that Covid drove two years of digital transformation in two months. The more digital our way of life becomes, the more areas that we can apply NLP models to create efficiencies
Network effects – From a market perspective, the value of NLPs will continue to compound as more and more people leverage the models. From a Hugging Face perspective, their value increases the more scientists, engineers, models, and datasets that enter the platform.
Uncertain
Speed of development – It is very unclear how fast two areas of the industry will develop: 1) the models and 2) general adoption. The first will drive the second. As the models improve, they become more applicable.
Challenges
Centralization / Winner-take-all – The largest challenge for Hugging Face will be if ultimately a handful of models (like GPT-3) begin to win full share. Overall, the more segmented and complex the NLP space becomes, the more valuable an open source platform like Hugging Face will be. If not, then people may choose to go directly to the handful of winners
Market sizing
28.7M software developers in 2024 (Source)
Pricing per month of tiered plan (Source)
Assume ~$700/mo per seat for Enterprise
Assume a regressive distribution
Est. market size in 2024 of ~$31.8B globally

Exhibit 11: Market sizing
Competition
There are three primary buckets of competition:
Direct – Companies like H20.ai, spaCy, AllenNLP, Gensim, and Fast.ai (non-exhaustive). H20.ai has >$150M in funding, and it champions themselves as the “#1 Machine Learning platform.” H20.ai is a more traditional corporate setup (selling a product), whereas Hugging Face is a two-sided platform (scientists and engineers) selling a community. The remainder of the competitors are less funded and seem to be more niche. Ultimately, many will succeed because the space is rapidly expanding, but the network effects, resources, and community aspects prime Hugging Face to win.
Platforms – The notable competitor here is GitHub. GitHub could definitely challenge Hugging Face, but currently, they work pretty closely together. As the network effects for Hugging Face builds, it would become increasingly challenging for GitHub to compete directly. I believe they will remain partners, and it would not surprise me if GitHub (Microsoft) attempts to acquire Hugging Face.
Scientists – The final group includes researchers. These would be the model development teams at other organizations. For NLP models, these would include Facebook, Google, and OpenAI. While they could restrict their models and challenge Hugging Face by going direct, the Hugging Face community has hit a level of size that is costly to withhold from. I see this competitive threat as low.
Additional Exhibits

Have to agree with your points on NLP. I can't emphasize enough how it is clearly going to change the future. When I try to explain it to my less tech-savvy friends, they easily get bored lol. I like what Hugging Face is doing and its clearly going to be the ML GitHub as you mentioned. This makes it altogether more important to have competition in this space. There are some competitors but they are not as good as Hugging Face is.
Why competition is important? Take the example of GPT-3 that Jeff mentioned right at the beginning. In the beginning, there were only three options that were widely known: Copysmith, Copy.ai and Conversion (now known as Jarvis). They were good but very limited in terms of features. After their initial launch, these companies didn't develop their products further for several months until the competition crept up. Their pricing was initially high IMO. But now there are loads of GPT-3 tools that are giving them a run for their money. For example, I tried this tool called Writecream yesterday. This product launched in June (just over 2 months ago while writing this comment) and it already has more features than Copy.ai or Conversion. Their development is lit and they are adding features so quickly that is mighty impressive plus their output quality is very good.
The reason I take the example of Writecream is because we need something similar to that which competes with Hugging Face. I hope the competition picks up pace because we really need it that much. More competition the better it is. I ranted lol but I hope you get the point