Part IV - Basic model training concepts
High-level concepts on how training works and the math behind it


A recap
In Part III of the AI series, we discussed more examples and the architecture of the concept behind all of these large language models (LLMs): the neural network.

The neural network consists of multiple layers (input layer, hidden layers, and output layers) that activate neurons to determine the proper output. The scoreboard example above shows a very high-level, simple example. How does a neural network know how to do this? The answer is training.
In Part IV, we will discuss high-level concepts for designing, training, and productionizing a model. I will include the usual disclaimers: I am not an ML researcher. AI/ML is moving too fast for this to be exhaustive. My goal is just to relay some concepts that can help any non-technical person level up their understanding of this space.
The concept behind training a model
Identifying numbers in Exhibit 1 is easy for you. You have learned those numbers. But what if I ask you to identify Chinese numerals? If you have never learned them, that would be hard.
Numbers are deterministic. There is a clear answer. For deciphering or generating text, it can be more challenging. Consider two examples. Fill in the blanks:
Example #1: “United States of _____”
Example #2: “Jeff is ____”
In example #1, you likely filled the blank with “America.” This is just pattern matching. You have seen “United States of” many times, and it is almost always followed by “America.”
In example #2, I would imagine the potential outcomes were much wider. If you connected this sentence to me, then you probably said, “cool”, “amazing”, or something else. Maybe your mind did not even go to me. You thought of other Jeffs you have met, and you produced a word associated with them.

Large Language Models (LLMs) are not too dissimilar. Basically, LLMs:
Consume a ton of information. Examples include public information like websites, documents, etc., and private information (if allowed) like user data.
Compress the knowledge into a neural network as depicted in Exhibit 1.
Respond with the highest probability answer based on all of the information it has consumed.
In the next few sections, we will go into more of the technical details, and we will follow the high-level steps of the model training process:
Section 1: Set the objective and constraints
Section 2: Data preparation
Section 3: Model design
Section 4: Training the model
Section 5: Fine-tuning
Section 6: Deploying the model
Section 1: Set the objective and constraints
Before beginning any work, the first question is: what is my objective? Having a clear perspective on the goal will impact all of the remaining sections. Here are some examples:
Data types: The objective will set the types of data you will prepare and train on. If you want general knowledge, you will need a variety of data types. If you want knowledge on a specific sector, you can potentially focus on that.
Budget: Training a model is expensive. If you have a finite budget, that will dictate the size of model you can train
Speed of model: Larger models take longer to run inference on. Training larger models improves knowledge, but there is a tradeoff of latency.
Build vs. Buy: There are many ways to use LLMs. You can train an LLM, but that is very resource-intensive. Depending on your objective, that may not be right for you. Instead, you can use an API for existing LLMs (e.g., OpenAI) or self-host and finetune an open-source model. This will be much cheaper.
For example, we trained a Code Complete model at Replit. We have proprietary data, and we do not have an endless budget. We wanted it to be imperceptibly fast, so we trained a three-billion-parameter model in-house.
Section 2: Data preparation
Once you define your objective, LLM pre-training starts with data. The more data an LLM consumes, the more knowledgeable it gets. LLM research is changing rapidly, but this rule seems to be holding steady (source). For data preparation, we will focus on two phases:
A. Collection
B. Pre-processing
(Note: Often people will call the portions leading to the base model “pre-training” instead of “training”. It’s highly confusing, and they are often used interchangeably. I will use “pre-training.”)
A. Collection
The first step is collecting the data. This will define what your LLM is pre-trained on. Within the constraints and budget defined in Section 1, gather the highest-quality data possible.
To give a sense of data scale, we can look at two large, general-purpose models like GPT-4 and Llama 2 70B. Llama 2 70B was developed by Meta, and it is open-source. Open-source means they have released all of the specifications of the model, so people can use it.

Llama 2 70B is trained on ~10 terabytes of text, which is roughly ten million books. The model processes all of that text on Graphics Processing Units (GPUs). Processing this data takes 6,000 GPUs running for 12 days straight, an estimated $2M.
GPT-4 is the model behind the ChatGPT breakthrough, but GPT-4 is closed-source, so we know much less about it. Leaks have suggested it is 1.76 TRILLION parameters. The data ingested was an order of magnitude larger, and it is estimated to have cost $50-100M to train.
Data collection can occur from various data sources. Some companies have large reservoirs of first-party data. For example, Facebook has a lot of text on its website. Depending on the terms of service, they may be able to use that information to train a model.
If you do not have first-party data, then you need to use public data. The ownership of this data is a highly contested legal topic right now. There is a concept called “web scraping.”
If you go to any webpage and right-click, you will see an option to “inspect.” The website HTML is open-source, and using a computer, you can easily go fetch all of this data and download it.
This is what OpenAI (and others) have done for large swaths of the internet. OpenAI would say the information was publicly accessible, so it was allowed. Publishers like the NY Times have sued them because they feel this was their first-party data. The exact rules of play for this area are still very much TBD by the courts.
A few key themes to highlight before we move on:
Data licensing deals have emerged for data collection. For example, OpenAI has inked deals with Reddit and Stack Overflow to use their data.
First-party data differentiates companies. If anyone can train on public information, then the only limiting factor is money for compute. But unique data sources will be a huge differentiator for players.
Litigation and regulation is slow. The courts are trying to define these rules of play, but AI is moving 100x faster. It’s unclear what will happen when the courts finally voice their opinion.
B. Pre-processing
The data collected often needs to be adjusted, so you can process it in pre-training. Some examples:
Removing HTML tags - When you scrape a webpage, you actually get the HTML code behind the page. So there are preparation steps to clean it into pure text.
Consistent formatting - You may scrape information from webpages that have weird formatting like extra white spaces, etc.
Lowercase - To simplify the inputs for the model, you may change all of the words to lowercase, so they are identical.
Think of it like making a salad. You can get all of the ingredients in the world, but if the produce is trash, it can only taste so good. The better the quality, the better the outcome. And if you are budget conscious, then you can probably save money by training on less, but higher quality data.
The data then gets tokenized. The words will ultimately be processed by the model as tokens. Here is an example:

On this site, you can type in a prompt, and the site will show you (via colors) how it will be tokenized. Each token is passed through the model sequentially. We will discuss this in greater depth in Part V.
Section 3: Model design
The next step is designing the model. There are many types of model architectures. Here are the three examples:
Recurrent Neural Networks (RNNs) - A bi-directional artificial neural network, meaning that it allows the output from some nodes to affect subsequent input to the same nodes. Processes data sequentially.
Convolutional Neural Networks (CNNs) - A uni-directional network (or feedforward neural network) where the data flows directly from input nodes to hidden nodes to output nodes.
Transformers - Leverage mechanisms like self-attention to process entire sequences simultaneously. The parallel process ability of Transformers makes it really good for natural language processing.
In Part I, we discussed the Transformer as a key breakthrough that eventually led to this GenAI surge. The actual design of a Transformer is actually quite complex:

In Part V, we will dive more directly into how each layer works. I like this 3D example. In designing the model, there are choices like:
Encoder-Decoder or Decoder-only - Transformers can have a process of an encoder (converts text to numbers) and decoder (converts numbers back to text). This is quite effective for things like translation: English → Numbers → Japanese. For generation, you may only need a Decoder, which is what ChatGPT does.
Number of layers and attention heads - In Part III, we showed neural networks have many layers. There are also concepts called Attention heads. Attention heads help analyze relationships between words. The number of layers and heads are defined in model design. For example, the original Transformer paper had eight attention heads.
Parameter size - Parameters come in two types: weights and biases. They are the nobs and dials that tune a model, and they are adjusted and tuned in training. Generally, larger parameter models are more effective than smaller, lower-parameter models. Larger models, however, are more expensive and slower.
Section 4: Pre-training the model
At this point, we have prepared a large dataset for the model to consume, and we have developed a design that we think will provide the best results. It’s time to start having this model consume the data and begin pre-training. To keep this very simple, let’s discuss two concepts:
A. Forward propagation - The model processes an input through the neural network and produces an output
B. Back-propagation - The quality of the output is measured, and the feedback is used to adjust the weights and biases of the model
As always, I will add the disclaimer around nuance and depth. There is more to pre-training, and I encourage you to read more!
A. Forward propagation
Pre-training starts by giving the model inputs to process. The inputs depend on the model objective and prepared data.

See the example above. The model is focused on spam detection for email subject lines. The prepared data has hundreds of thousands of email subject lines that are already classified as spam or not spam. Then the email is provided to the model. The model makes an assessment. If it’s right, then great! If it’s wrong, then the weights and biases are adjusted.
Models cannot actually read. It’s all math and calculations. The model converts the input into numbers, runs a bunch of calculations, and then produces an output that’s converted back to the desired format.

Still confusing. Let’s go a bit deeper.
In the section before, we discussed tokenization. The data is converted into digestible tokens. The model converts each token into numbers. These numbers are called vector embeddings. For example, if the model is processing the words in Exhibit 5:

We will discuss the actual meaning of the numbers in the step-by-step of the Transformer in Part V. For now, the key concept is that these long vectors of numbers are a format the model can understand. Once the input text, image, etc., is converted to vectors, the input begins passing through the layers of the neural network. Each hidden layer has some number of neurons. At each neuron, there are three key concepts:
Weight
Bias
Activation function
As mentioned earlier, the weight and biases are the nobs and dials used to train the model. A weight is a parameter that adjusts the strength of the connection between the current neuron and the neurons in the next layer.

Every neuron For example, we will click into one of the hidden layers from Exhibit 9 of Part III. The first neuron in layer #2 (outlined in red) is connected to five neurons in the next layer. For each connection, there is a weight that controls the strength of the connection between neurons (ex., w21, w22, w23, w24, and w25).
Notice also that the first neuron has four lines connected to it from the input layer. Four different weights feed into the neuron. Each line represents a weight. The weight, however, is just one part of this connection. There is also a bias and an activation function.
The bias is a parameter added that adjusts the output based on biases in the data. Previously, we talked about the number of parameters in a model (in hundreds of billions or trillions). The weights and biases are the parameters! These numbers are all calculated, and they produce a real number = z. The official equation is:
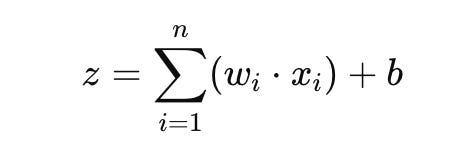
This may look intimidating, but here’s how it works in practice:

Each previous neuron has a value (x1, x2, x3, x4). The value is multiplied by the corresponding weight (ex., w11, w12, w13, w14). The product of each is added together to get the sum. Then the bias (ex., b) for the neuron is added. This gives a final output: z.

This number then becomes an x-axis coordinate for an activation function. Activation functions can be complex and highly variable across models. Basically, they are non-linear functions that can help fit complex patterns in data. This produces a y-axis coordinate on the line. That becomes our output for the next layers. Here’s a good walkthrough from Statquest.
This repeats through every neuron and hidden layer until a number is produced at the output layer. The output number is converted back to the desired output (e.g., text), and that’s the model output!
These parameters start at a basic level, and they are likely pretty inaccurate. But when you do this billions and trillions of times, they start to get much more accurate. They continuously improve using the concept of backpropagation.
B. Backpropagation
To understand backpropagation, we will think of two main concepts:
Error function
Gradient descent
The error function measures how far the model result was from the desired result. Gradient descent is an optimization algorithm that tweaks parameters to reduce that error.
For example, let’s say I pick a random number between 1 and 10. You guess 7, but the answer is 5. The error function would calculate the difference between the answer (5) and your guess (7). I tell you that you were two numbers off.
Now, you know the answer is either 5 (7-2) or 9 (7+2). So you guess 9. I say that you are now four off. The error function has increased, which means you are further from the correct answer. Gradient descent is the process of optimizing the error function to be lower. So now, you know to guess lower.

For the model, there are millions of weights. The math is extremely complex, but the logic remains. Run a prediction. Calculate the total error. Adjust the weights and biases to reduce the error. Rinse and repeat to improve the model. Watch this video for a full explanation.
It’s all math. Trillions of calculations. Now you know why so many computers are needed!
Knowing the “right” answer is a bit confusing. There are many training methods, but here are three that may help explain basic concepts:
A. Supervised learning
B. Unsupervised learning
C. Masked language modeling
A. Supervised learning
The first concept is supervised learning. Supervised learning is a type of machine learning where the model is trained on labeled data. Labeled data means that we know both the input and the correct output.
We run the input through the model. The output is produced. We compare it to the correct output using the error function. Then we use gradient descent to adjust the weights and biases. Then we move to the next input/output pairing and try again.
Hot Dog or not hot dog is a funny example from the show Silicon Valley. Basically, you show the model a food, and it determines if it’s a hot dog or not. This example is comically unuseful (except it sells as a way to identify predators on webcam sites… you can do the math), but the same logic in training applies to other use cases.
B. Unsupervised learning
Unsupervised learning does not have labeled answers. In unsupervised learning, the model takes in swathes of data with no guidance and identifies patterns and relationships.
Supervised learning could be really effective if you have a specific goal the model needs to accomplish (like identifying a hot dog). Unsupervised learning is helpful if you do not have that specific goal.

Here’s an example. Suppose you had a random plot of data on the lefthand-side of Exhibit 16. You run a model to identify patterns, and it finds three clusters of “similar” data points. This could be certain types of user behavior to detect bank fraud or risky lendees, etc.
C. Masked language model
For things like natural text, it may be hard to know what’s “right” and what’s “wrong.” One interesting concept that makes intuitive sense is masked language modeling. In this process, you hide specific tokens in the input, and you have the model predict the missing token.

Some of the examples above are totally subjective. The model does this for massive amounts of data, and it begins learning the most likely answer.
Pre-training conclusion
These are just some basic concepts to understand what pre-training a model actually is. As the data scales, theoretically, the model parameters get more accurate, and the neural network gets more accurate. At the end of this process, you have a base model that can be used.
Section 5: Post-training the model
Once the base model is complete, it can be used. When someone prompts or queries the model, it is referred to as inference. Put more clearly, when you type something into ChatGPT, that’s the prompt. When you hit enter, the prompt is passed to the model as an input, and the model produces the output. This is model inference.
It’s worth noting, however, that the base model can be adapted. You can do incremental training which is called post-training. There are two primary concepts to share here that I think are most interesting:
A. Finetuning - The process of post-training the model on an incremental data set to achieve a specific task or use case
B. Reinforcement Learning from Human Feedback (RLHF) - Post-training the model based on user feedback
A. Finetuning
Many applications of LLMs involve very specific use cases. For example, you may want to build a product that uses AI to answer medical questions. You could train a model from scratch, but that is very time-consuming and expensive.
Alternatively, you could use an open-source model or a model you have already trained, but if neither is designed for the specific use case, then you are stuck. Here’s where finetuning comes in. Here’s how it works:
Select a base model
Curate a dataset of training data specific to your use case
Post-train the model on the dataset, and adjust the weights to your use case
Finetuning can be extremely effective at boosting performance for a specific use case and is far more cost-effective.
This is a bull case for open source. People can host their own open-source models and finetune them to their needs, extending AI access to people who cannot train models from scratch.
B. Reinforcement Learning from Human Feedback (RLHF)
RLHF relies on user feedback to provide data for fine-tuning the model. Rather than having a curated dataset, the model generates an output, and then human feedback is provided.
For example, a model could produce two outputs and ask the user which they prefer. Each output could have a thumbs-up or thumbs-down option to gauge satisfaction. The results of these surveys are used to post-train the model.
Section 6: In production
Once the model is mostly complete, it’s time to prepare it for production so you can run inference on it. Here are some examples of some of the considerations:
A. Deploying the model
B. User experience (UX)
C. Risks
A. Deploying the model
The neural network must be running on a computer to use the model. The model is both trained and run in production on a Graphic Processing Unit (GPU). If you have heard about the explosion of Nvidia stock, it’s because they make the best GPUs in the world. A GPU is much better at parallel calculations than a traditional CPU.
Demand planning is an important part of this. Depending on the amount of usage you expect the model to get, you may need a larger or smaller capacity. You could be running a model for a small internal service or need ~30,000 GPUs to run ChatGPT. If you run out of resources, your application will go down, costing you time and/or money. But a GPU costs ~$25,000, so you also do not want to have way too many; otherwise, your cost will be high.
This is why cloud providers like Amazon Web Services and Google Cloud are so great. Rather than try to predict demand and purchase your own GPUs, you can scale up and scale down within their data centers relatively quickly based on real-time demand.
B. User experience (UX)
Your model may be used by a variety of individuals. Particularly if it is a consumer-facing application, the UX matters. If the UX is poor, people will not continue to use the model. Questions like:
Do the users know how to use the model?
Do they enjoy using the model?
Some basic examples are concepts like suggested prompts and model streaming. Models are a new concept, so many people may not understand how to use them. Most consumer-facing LLMs have suggestions to help get people started:

Once a model is prompted, it needs a little time to run calculations. Model streaming is the process of delivering the response as it’s generated. Here are two different examples:

Notice how ChatGPT jumps by each word, but Google slowly appears. This is a UX choice by each. There are many small touches people do to help productionize a model and make it more approachable.
C. Risks
The magic of models is that they are non-deterministic. This makes them unpredictable, and depending on your use case, there could be some risks. For example, there’s a famous story of a chatbot being tricked into selling a car for $1. While this is a funny story in hindsight, actions like these can have real business impacts, and there are even worse examples like racial slurs and more.
Closing thoughts
At this point, you should have enough high-level concepts on designing LLMs, pre-training, post-training, and production to be dangerous. In the next part, we will go even deeper on the individual layers of a Transformer model.
I've been waiting for you to post again, :) Just read your article on Sutter Hill Ventures too, great stuff!